Big Data Processing is an inherent problem when dealing with domains that provide large volumes of data to be used in ML model training or directly into analytical pipelines. The state of the art for Big Data Processing adopts distributed frameworks, such as Apache Spark and Apache Flink, and involves research that revisits some of the technique developed in databases that have to be rethought for this new Big Data scenario. The topic involve, but are not resumed to: dataflow optimization; multi-plataform dataflw planning and execution; data lake systems and big data storage; big data partitioning algorithms etc...

Data Centric Ai enconpasses a series of techniques and methods that focus on the improvement of AI model performance by means of optimizing data quality.
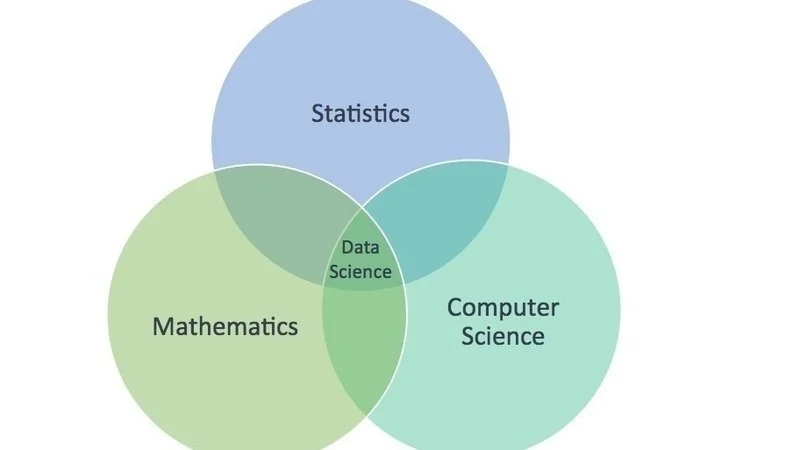
This research area involves applying statistical tools and machine learning techniques to solve some applied problems.

This research area investigates data-centric techniques to make sure that built models do not exhibit properties that hurt ethical principals and is not biased towards majority demographic groups.

Green Ai involves thinking the AI process and a potential consumer of extensive resources used to compute the training of large models. In this context, this research area is interested in developing new techniques that target reducing the consumption of electricity and other resources needed for Ai task fulfillment.

The development of technologies that generate large amounts of data (high-throughput) from different omics (genome, transcriptome, metagenome, among others) has created the need to develop strategies to analyze, integrate, and interpret this enormous amount of data (big data). Although a wide variety of statistical methods have been designed to analyze big data, experience using artificial intelligence (AI) techniques suggests that these methods are the most appropriate. The Bioinformatics Laboratory has applied different AI techniques related to human, animal, plant health studies and biotechnological applications.

Knowledge graphs (KG) are data representations in graphs that emphasize the relationship between entities in nodes. KGs are extensively used in semantically rich domains. They require the application of new methods that enable large KGs analysis; learning features of a KG; predict links in KGs etc.

This is a broad research area involving techniques in the context of data-driven model construction and evaluation. It also includes an applied perspective where ML techniques are applied to solve specific prediction problems in some scientific or business application.

This research aims at developing a new class of systems that support different phases of the machine learning life cycle. It involves managing data, and data life-cycle, model, and model life-cycle, and the dataflows used to process data and models